What is MDTM?
The Problem
Multicore and manycore have become the norm for high-performance computing. These new architectures provide advanced features that can be exploited to design and implement a new generation of high-performance data movement tools. To date, numerous efforts have been made to exploit multicore parallelism to speed up data transfer performance. However, existing data movement tools are still bound by major inefficiencies when running on multicore systems for the following reasons:
Existing data transfer tools are unable to fully and efficiently exploit multicore hardware under the default OS support, especially on NUMA systems.
The disconnect between software and multicore hardware renders network I/O processing on multicore systems inefficient.
On NUMA systems, the performance gap between disk and networking devices cannot be effectively narrowed or hidden under the default OS support.
The Multicore-Aware Data Transfer Middleware (MDTM) Project
To address these inefficiencies and limitations, DOE Advanced Scientific Computing Research (ASCR) office has funded Fermilab network research group to work on the Multicore-Aware Data Transfer Middleware (MDTM) project. MDTM seeks to accelerate data movement toolkits at multicore systems.
MDTM consists of two major components (Figure 1):
- MDTM middleware, which aims to research and develop a user-space resource scheduler that harnesses multicore parallelism to scale data movement tools on multicore systems.
- mdtmFTP, which aims to research and develop a high-performance data transfer tool to optimize data transfer on multicore systems.
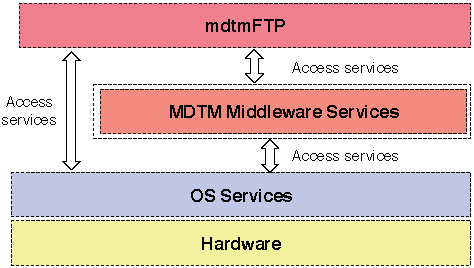
Figure 1 MDTM System Architecture
Research Team
- Liang Zhang, Email: liangz@fnal.gov
- Lauri Loebel Carpenter, Email: lauri@fnal.gov
- Phil DeMar, Email: demar@fnal.gov
- Wenji Wu (PI), Email: wenji@fnal.gov
- Last modified
- 02/14/2019