mdtmFTP: A High-performance Data Transfer Tool
mdtmFTP is a high-performance data transfer tool that builds upon the MDTM middleware. It has several salient features:
-
It adopts a pipelined I/O-centric architecture to execute data transfer tasks. Dedicated I/O threads are spawned to perform network and disk I/O operations
-
It utilizes the MDTM middleware services to make optimal use of the underlying multicore system.
-
It implements a large virtual file mechanism to address the Lots of Small File (LOSF) problems
-
Zero copy, asynchronous I/O, pipelining, batch processing, and buffer-pool mechanisms are applied to optimize performance
A Pipelined I/O-Centric Design
mdtmFTP adopts a pipelined I/O centric design. A data transfer task is carried out in a pipelined manner across multiple cores. Dedicated I/O threads are spawned to perform network and disk I/O operations in parallel
mdtmFTP handles two types of I/O device, storage/disk(s) and NIC(s). Depending on a device’s I/O capability, one or multiple threads are spawned for each I/O device. Typically, four types of I/O threads will be spawned:
-
Disk/storage reader threads to read data from disks or storage systems.
-
Disk/storage writer threads to write data to disks or storage systems.
-
Network sender threads to send data to networks via NIC.
-
Network receiver threads to receives data from network via NIC.
In addition to the I/O threads, mdtmFTP spawns management threads to handle user requests, and management-related functions.
mdtmFTP calls MDTM middleware scheduling service to schedule cores for its threads. For each I/O thread, MDTM middleware first selects a core near the I/O device (e.g., NIC or disk) the thread uses, and then pins the thread to the chosen core. This strategy has two benefits: (1) it enforces I/O locality on NUMA systems; (2) it avoids I/O thread migrations, thus providing core affinity for I/O operations. Therefore, mdtmFTP performance can be significantly improved. Typically, an I/O thread is dedicated with a single core. No other threads will be scheduled to a core that an I/O thread has been assigned to.
In addition, MDTM middleware partitions system cores into two zones – MDTM zone and non-MDTM zone. mdtmFTP runs in the MDTM-zone while other applications are confined within the non-MDTM-zone. This strategy reduces other applications’ interference to mdtmFTP, thus resulting in optimum data transfer performance.
High-performance data transfer involves a significant amount of memory buffer operations. To avoid costly memory allocation/deallocation in the critical data path of data transfer, mdtmFTP pre-allocates multiple data buffers, and manages them in a data buffer pool. Data buffers are pinned and locked so as to avoid being paged to the swap area and memory migration. Data buffers are recycled and reused.
mdtmFTP executes data transfers in a pipelined manner. In the sender, management threads first preprocess data transfer requests. A data transfer task is typically split into multiple subtasks. A subtask can comprise file segments, a group of files, or file folders. Subtasks are then put in a task queue. Disk/storage reader threads keep fetching subtasks from the task queue. For each subtask, data will be first fetched from storage/disk(s) into empty buffers. Filled data buffers are temporarily put in a buffer queue. Concurrently, network sender threads continue fetching filled data buffers from the buffer queue, and send data to the network in parallel on multiple TCP streams. In the receiver, data will be received into empty buffers via network receiver threads; afterwards, the filled buffers will be passed over to storage/disk writer threads to store data into storage/disk(s).
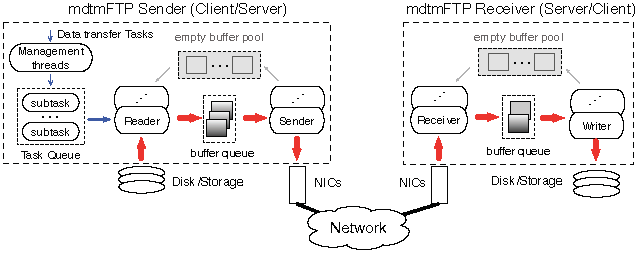
Figure 2 A Pipelined I/O Centric Design
A Large Virtual File Transfer Mechanism to Address the LOSF Problem
Existing data transfer tools are unable to effectively address the LOSF problem. GridFTP uses pipelining and concurrency to address the inefficiency in LOSF. However, GridFTP's data transfer performance is not satisfying. Some data transfer applications such as BBCP make a tar ball of the dataset and then transfer the tar ball as one file. The problem is the “tar†process might involve significant amount of disk/memory operations, which is normally costly and slow.
mdtmFTP implements a large virtual file mechanism to address the LOSF problem. The mechanism works as shown in Figure 3.
-
A mdtmFTP sender receives a request to transfer a dataset to a mdtmFTP receiver. The sender quickly traverses the dataset, and creates a large "virtual" file for the dataset. Logically, each file in the dataset, which include regular files, folders, and symbolic links, is treated as a file segment in the virtual file. Each file in the dataset is sequentially added to the virtual file with start position and end position. The virtual file is not physically created. Instead, a content index table is created to maintain metadata for the virtual file. The content index table consists of entries. Each entry corresponds to a file in the dataset. It records the file's metadata, such as file name, path, type, and its start and end positons in the virtual file.
The sender serializes the content index table and transmits it to the receiver.
The receiver deserializes and reconstructs the content index table, and then asks for data transfer.
Using the content index created earlier, the sender continuously reads data blocks from disk and sends them out to networks. The whole dataset is transferred continuously and seamlessly as a single virtual file in one or multiple TCP streams.
When receiving a data block from the sender, the receiver first looks up the content index table to determine which file the data block belongs to and its positon with the file, and then store the data block into disk/storage.
Our large virtual file mechanism has two benefits: (1) it eliminates protocol processing between the sender and receiver on a per-file basis. And (2) it allows for batch processing small files in the sender and receiver. Therefore, I/O performance can be optimized.
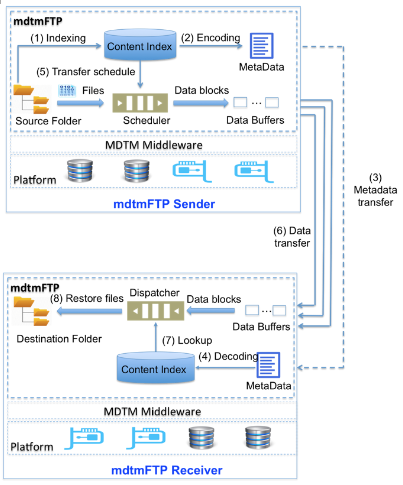
Figure 3 Large Virtual File Transfer Mechanism
- Last modified
- 02/14/2019